
Spring Data JPA 是一个强大的工具,用于在 Java 应用程序中处理数据库。它为查询和持久化数据提供了一个易于使用且灵活的接口,并且可以显著简化数据访问层。但是,如同其他工具一样,正确使用 Spring Data JPA 来获得最佳性能和效率非常重要。

在本文中,我们将探索使用 Spring Data JPA 优化性能的一些技巧和最佳实践。
N+1查询问题是指在使用延迟加载机制时,当我们查询一个实体对象及其关联对象时,由于需要每次查询相应的关联对象,所以就会发生多次查询数据库的情况。例如,我们查询一个包含 N 个订单的用户,而每个订单又包含 M 个商品,则会发生 (N+1)*M 次查询数据库的情况,其中 N+1 是因为查询用户时也需要进行一次查询。
这种情况下,当数据量较大时,就会导致性能问题和资源浪费。因此,在使用
Spring Data JPA 时,应注意避免 N+1 查询问题,从而提高查询效率。
解决 N+1 查询问题有以下几种方式:
在定义实体类时,可以使用 @OneToMany 或 @ManyToOne 注解中的 fetch 属性将关联对象改为即时加载模式。但需要注意,如果关联对象数量较大,可能会影响性能。
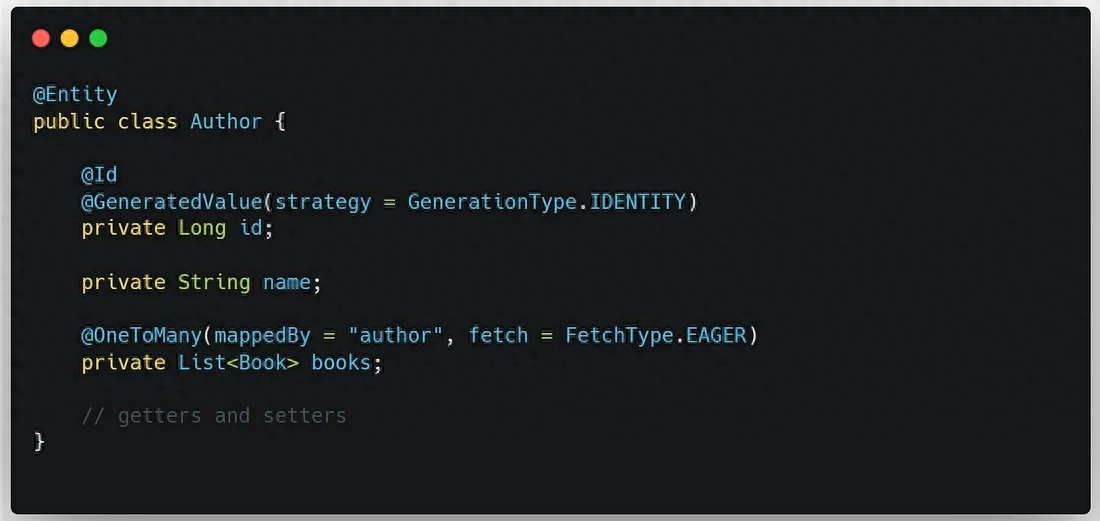

@BatchSize 注解可以控制 Hibernate 在加载关联对象时一次性加载的个数。例如,设置 @BatchSize(size = 100) 后,Hibernate 将会在一次查询中加载 100 个关联对象。
使用 JPQL(Java Persistence Query Language)或 Criteria API 构建查询语句时,可以使用 JOIN FETCH 关键字来实现关联查询,从而一次性加载关联对象。
EntityGraph 是 JPA 2.1 中引入的一种机制,可以预定义实体类的加载图(Load Graph),并在查询时指定该加载图,从而控制关联对象的加载方式。例如,可以使用 @NamedEntityGraph 注解在实体类上定义加载图,然后在查询时使用 @EntityGraph 注解指定该加载图。
需要注意的是,采用以上几种方式来解决 N+1 查询问题时,需要根据具体情况进行选择和调整,避免出现新的性能问题。
延迟加载是一种将对象或数据的加载延迟到需要时才加载的技术。换句话说,延迟加载不是一次加载所有数据,而是在请求时只加载所需的数据。这可以通过减少加载到内存中的不必要数据量来节省大量时间和资源。
Spring Data JPA 支持两种加载方式:即时加载(Eager loading)和延迟加载(Lazy loading)。即时加载是指在查询实体对象时,将其关联的所有对象都一并加载;而延迟加载则是指只有在需要使用到关联对象时才进行加载。
下面是使用 Spring Data JPA 延迟加载的示例代码:
@Entity
public class Order {
@Id
private Long id;
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY)
private List<Item> items;
// getters and setters
}
@Entity
public class Item {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Order order;
// getters and setters
}在上述代码中,我们通过设置 @ManyToOne 和 @OneToMany 注解的 fetch 属性为 FetchType.LAZY 来实现延迟加载。当我们查询订单对象时,与之关联的商品列表并不会立即加载,只有当需要访问该列表时才会进行加载。
需要注意的是,如果在延迟加载模式下访问了未初始化的集合属性,就会抛出
org.hibernate.LazyInitializationException 异常。为了避免这种情况,可以将实体类及其关联对象一起加载,或者手动使用 Hibernate.initialize() 方法进行初始化。
缓存是一种用于将经常使用的数据存储在内存中以便可以更快地访问的技术。这可以显著减少数据库查询的数量并提高应用程序的性能。Spring Data JPA 使用 Ehcache、Hazelcast、Infinispan、Redis 等流行的缓存框架为缓存提供内置支持。
Spring Data JPA 支持一级缓存和二级缓存。一级缓存是指在同一个事务下,对于相同的实体对象,第二次查询时直接从缓存中获取数据,而不需要再次查询数据库;二级缓存则是指多个事务之间共享同一个缓存区域。
下面是使用 Spring Data JPA 缓存的示例代码:
@Repository
public class OrderRepositoryImpl implements OrderRepository {
@PersistenceContext
private EntityManager em;
@Override
@Transactional(readOnly = true)
public Order findById(Long id) {
return em.find(Order.class, id);
}
}在上述代码中,我们通过 @PersistenceContext 注解注入了 EntityManager 对象,并在查询时开启了只读事务。由于在同一个事务下,EntityManager 对象会自动缓存查询过的实体对象,因此当我们多次查询同一个订单对象时,第二次查询将直接从缓存中获取,而不需要再次查询数据库。
@Entity
@Cacheable(true)
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class Order {
// ...
}
@Configuration
@EnableCaching
public class CacheConfig extends CachingConfigurerSupport {
@Bean
public CacheManager cacheManager() {
return new EhCacheCacheManager(ehCacheManager());
}
@Bean
public EhCacheManagerFactoryBean ehCacheManager() {
EhCacheManagerFactoryBean factory = new EhCacheManagerFactoryBean();
factory.setConfigLocation(new ClassPathResource("ehcache.xml"));
factory.setShared(true);
return factory;
}
}在上述代码中,我们使用 @Cacheable 和 @Cache 注解对实体类进行缓存配置,并在配置类中开启了缓存支持。同时,我们还需要在类路径下添加一个名为 ehcache.xml 的 Ehcache 配置文件。
需要注意的是,使用二级缓存时需要谨慎,应根据具体的业务需求和系统性能要求来选择使用何种类型的缓存,并合理配置相应的缓存策略。
分页和排序是用于限制查询返回的结果数量并根据特定条件对结果进行排序的技术。在 Spring Data JPA 中,这些技术是使用接口实现的Pageable,该接口允许你指定页面大小、排序标准和页码。
下面是使用 Spring Data JPA 分页和排序的示例代码:
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
Page<Order> findAll(Pageable pageable);
}在上述代码中,我们通过继承 JpaRepository 接口来继承 Spring Data JPA 提供的通用方法,并定义了一个名为 findAll 的方法并添加 Pageable 参数,从而实现分页查询功能。在调用该方法时,可以传入一个 PageRequest 对象来指定查询的页数、每页数据量以及排序方式等。
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
List<Order> findByStatus(String status, Sort sort);
}在上述代码中,我们定义了一个名为 findByStatus 的方法并添加 Sort 参数,从而实现根据状态字段进行排序的查询功能。在调用该方法时,可以传入一个 Sort 对象来指定排序方式。
需要注意的是,在使用分页和排序功能时,应尽可能减少查询的数据量,避免出现性能问题。例如,可以使用查询条件来限制查询的范围,或者对数据库表建立索引等方式进行优化。
使用 Spring Data JPA 与数据库交互时,优化性能以确保有效利用资源和更快的响应时间非常重要。上述几种技术可用于实现此目的:
